Emotion Recognition with Multi-task Learning
Introduction
I am a beginner in Data Science and currently working on a learning project aimed at emotion recognition from a bio-medical sensor dataset.
The dataset consists of 8 sensors data from 20 subjects, here I have attached a screenshot of a very small part of the dataset to give you better insight into it:

So, as you can see, the Dataset is about:
- Multiple subjects and for each subject, there are 11 columns of data.
- Columns 1-8 are raw sensor data (EEG, EOG, GSR, Skin Temperature, IR Response, ... ) at 250 Hz.
- Columns 9-11 are the corresponding labels.
What I want to do?
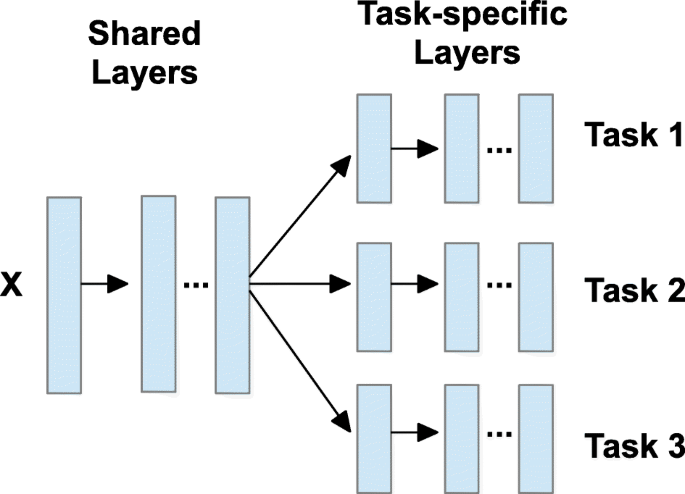
I want to use a Multi-task Learning to generate the output of three emotion levels - Arousal, Dominance Valance.
I did lots of research about it but unfortunately didn't find any clear guidance on what I should do. I found something related to VAD model, but not certain how to implement it for this dataset.
So, if someone could give me a guideline or path (the main steps that I should do) to work on it, I can search about it and also try to solve it step by step.
Topic machine-learning-model multitask-learning machine-learning
Category Data Science