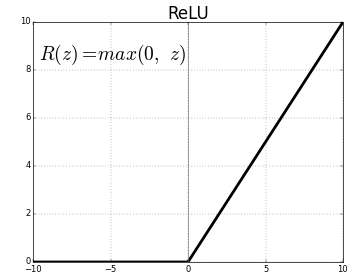
Why is ReLU used as an activation function?
Activation functions are used to introduce non-linearities in the linear output of the type w * x + b in a neural network.
Which I am able to understand intuitively for the activation functions like sigmoid.
I understand the advantages of ReLU, which is avoiding dead neurons during backpropagation. However, I am not able to understand why is ReLU used as an activation function if its output is linear?
Doesn't the whole point of being the activation function get defeated if it won't introduce non-linearity?
Topic activation-function deep-learning neural-network machine-learning
Category Data Science